From Embeddings to Queries: Navigating the Basics of Large Language Models
In today’s landscape, Large Language Models (LLMs) are pivotal, driving advancements in natural language understanding. We’re about to dive into the basics of LLMs (like how they play with words, understand queries, and more), how to interact with them using the LlamaIndex framework, and the game-changing process of prompt augmentation with RAG by integrating custom data.
What is a Large Language Model?
A Large Language Model (LLM) refers to a deep learning algorithm, predominantly leveraging transformer architectures (a neural network architecture introduced by Google), capable of executing a diverse range of Natural Language Processing (NLP) tasks. These models, trained on extensive datasets, stand out for their exceptional proficiency in attaining a broad spectrum of language understanding and generation, making them adept at general-purpose applications.

Popular examples of LLMs include OpenAI’s GPT series (e.g., GPT-3 a.k.a. Generative Pre-trained Transformer 3), Llama 2 (from Meta), and others.
Key concepts
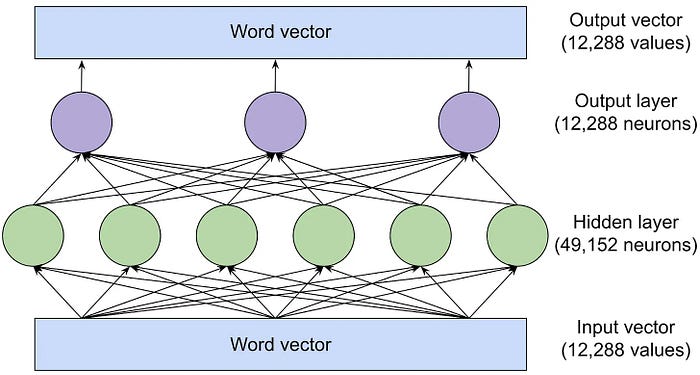
The embedding layer is responsible for mapping words or phrases from the vocabulary to vectors of real numbers, thereby creating word vectors. Since words are too complex to represent in just two dimensions, language models use vector spaces with hundreds, or even thousands, of dimensions. For example, this is one way to represent "dog" as a vector (the full vector is composed of 300 numbers):
[-0.03301828354597092, 0.05134638026356697, 0.0036009703762829304, ..., -0.04278775304555893]Each word vector represents a point in an imaginary “word space,” and words with more similar meanings are placed closer together. For instance, the words closest to a dog in vector space include cat, animal, and pet.

The attention mechanism is where words actively search their surroundings to identify other words with pertinent context, fostering the exchange of information among them. Each word makes a checklist (query vector) describing the characteristics of the words it is looking for and concurrently generates another checklist (key vector) describing its characteristics. The network evaluates each key vector with each query vector (using dot product) to identify words that match. When such a match is found, it shares information from the word that produced the key vector to the one that produced the query vector.

The feed-forward layer examines one word at a time (no information is exchanged between words) and tries to predict the next word. It performs tentative prediction about the next word based on the contextual information in the relative word vector previously generated by the attention mechanism.
Having grasped the fundamentals, let’s explore LlamaIndex and discover how we can utilize it to augment existing LLMs with custom data and beyond.
Why LlamaIndex?
LlamaIndex is a versatile and uncomplicated data framework tailored for linking custom data sources with expansive language models, offering essential tools to enhance applications using LLMs. The framework encompasses the following key functionalities:
- Data Ingestion: Seamlessly connect your diverse existing data sources, spanning various formats such as APIs, PDFs, documents, SQL, and more. This integration enables the utilization of these sources within applications powered by large language models.
- Data Indexing: Efficiently store and index your data to accommodate diverse use cases. LlamaIndex facilitates integration with downstream vector stores and database providers, enhancing the accessibility and retrieval of information.
- Query Interface: LlamaIndex features a user-friendly query interface capable of processing any input prompt related to your data. By employing this interface, you can obtain knowledge-rich responses, contributing to a more informed and contextually relevant user experience.
There are many noteworthy alternatives or similar options for language models, data frameworks, or related technologies, such as LangChain and Hugging Face Transformers.
LLM Prompt Augmentation
LLMs are trained on huge datasets, but they lack training on your specific data. Retrieval-augmented generation (RAG) fills this gap by incorporating your data into the existing dataset available to LLMs.
Within RAG, your data is loaded and prepared for queries, a process known as "indexing". User queries interact with this index, refining your data to the most relevant context. This refined context, along with your query and a prompt, is then presented to the RAG, which generates a response.
Whether you’re building a chatbot or an agent, understanding RAG techniques for integrating data into your application is essential.

Within the RAG there are five key stages:
- Loading: This involves acquiring your data from its source, whether it’s stored in text files, PDFs, another website, a database, or an API.
- Indexing: Involves generating vector embeddings and employing various metadata strategies to facilitate accurate retrieval of contextually relevant information.
- Storage: After indexing, storing the index and associated metadata is often beneficial to avoid the need for future reindexing.
- Retrieve: With various indexing strategies available, you can use LLM data structures for querying, using techniques such as sub-queries, multi-step queries, and hybrid strategies.
- Evaluation: It provides objective metrics to measure the accuracy, fidelity, and speed of your responses to queries.
Chat with your data
LlamaIndex uses OpenAI’s gpt-3.5-turbo by default so we have to export the API key by setting it as an environment variable (create one here if you don't have one):
import os
os.environ['OPENAI_API_KEY'] = "sk-<your-key-here>"In the same folder where the Python script was created, create a data folder which (in the example below) consists of one text file, but could contain many documents. The directory structure should look like this:
├── main.py
└── data
└── your_secret_file.txtWe can now proceed on loading the data and building an index — a data structure that allows us to quickly retrieve relevant context for a user query — over the documents:
from llama_index import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
# Load data
documents = SimpleDirectoryReader("data").load_data()
# Define chunk_size in order to parse documents into smaller chunks
service_context = ServiceContext.from_defaults(chunk_size=512)
# Builds an index over the documents in the data folder
index = VectorStoreIndex.from_documents(documents, service_context=service_context, show_progress=True)Everything is set for building a chat engine from the index and having a conversation with our data:
# Set to stream the response back and configure
# the retriever to get more context (top 3 most similar documents)
chat_engine = index.as_chat_engine(similarity_top_k=3, chat_mode="context")
streaming_response = chat_engine.stream_chat("Your query here?")
for token in streaming_response.response_gen:
print(token, end="")Storing the index
To avoid loading and building the index each time, we can persist the embeddings to a storage layer:
index.storage_context.persist(persist_dir="./data_storage")Of course, we don’t get the benefits of persisting unless we load the data. So we can generate and store the index if it doesn’t exist, but load it if it does:
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
STORAGE_DIRECTORY = "./data_storage"
# Check if storage already exists
if not os.path.exists(STORAGE_DIRECTORY):
# Load data
documents = SimpleDirectoryReader("data").load_data()
# Define chunk_size in order to parse documents into smaller chunks
service_context = ServiceContext.from_defaults(chunk_size=512)
# Builds an index over the documents in the data folder
index = VectorStoreIndex.from_documents(documents, service_context=service_context, show_progress=True)
# Store it for later
index.storage_context.persist(persist_dir=STORAGE_DIRECTORY)
else:
# Load the existing index
storage_context = StorageContext.from_defaults(persist_dir=STORAGE_DIRECTORY)
index = load_index_from_storage(storage_context)
chat_engine = index.as_chat_engine(similarity_top_k=3, chat_mode="context")
streaming_response = chat_engine.stream_chat("Your query here?")
for token in streaming_response.response_gen:
print(token, end="")You can find the full source code (with additional data integration i.e., load documents from web pages, pdf, JSON; how to use a local LLM, and more) on my GitHub.
Conclusion
In essence, our exploration into the fundamentals of Large Language Models (LLMs) and the intricacies of prompt augmentation with custom data unveils the tip of the iceberg in this vast and complex domain. While we’ve navigated the crucial steps of data ingestion, indexing, and querying with frameworks like llama-index, this journey is merely the inception.
The expansive realm of LLMs holds myriad layers yet to be uncovered, presenting continuous opportunities for innovation and refinement. As we grasp the essentials, it becomes evident that the dynamic landscape of natural language processing offers a rich tapestry of challenges and possibilities. The path ahead promises further revelations, encouraging ongoing exploration and discovery in the ever-evolving world of large language models.